 eDiscovery
eDiscovery Collections
Collections Processing
Processing Early Case Assessment
Early Case Assessment Information Governance
Information Governance Data Migration
Data Migration Data Archiving
Data Archiving Platform Services
Platform Services Connectors
Connectors Platform API
Platform API Pricing Plans
Pricing Plans Professional Services
Professional Services Technical Support
Technical Support Partnerships
Partnerships About us
About us Careers
Careers Newsroom
Newsroom Reveal
Reveal Logikcull by Reveal
Logikcull by Reveal Events
Events Webinars
Webinars OnnAcademy
OnnAcademy Blog
Blog Content Library
Content Library Trust Center
Trust Center Developer Hub
Developer Hub
Editor’s note: This post was originally published in March 2021 and has been completely revamped and updated for accuracy, relevance, and comprehensiveness.
Introduction
Welcome to the beginner’s guide to Zendesk eDiscovery, where we’ll cover everything you need to know about eDiscovery for Zendesk, a cutting-edge customer relationship management (CRM) software platform focused on helping businesses improve their customer experience. From an advanced ticketing system to AI-powered chat bots, Zendesk’s suite of products helps businesses automate their customer support efforts with an all-in-one solution. Managing 170,000 accounts across 160 countries, Zendesk hit its $1 billion revenue milestone in 2020, cementing its status as a top CRM contender.
Our increasing acceptance of hybrid and remote workplaces has only added to Zendesk’s momentum. Working from a distance has pushed companies to prioritize connectivity and communication in all areas of business, and customer experience often sits at the top. Customers are, after all, the lifeblood of any business — which makes their requests, questions, and complaints (and support agents’ responses) critical data. A single Zendesk ticket can hold sensitive communications, attachments, and personal information that may become relevant for legal and regulatory reasons. Having a way to easily find and produce the right data is essential, which is why having a Zendesk eDiscovery strategy is quickly becoming a priority for many companies.
In this guide, we’ll help you understand how Zendesk works, what kind of data it holds, and how to collect that data. We’ll also leave you with a flexible Zendesk eDiscovery strategy you can adapt to your needs.
Disclaimer: Zendesk also offers a sales automation product, Zendesk for sales, but we will only cover eDiscovery for Zendesk for service in this guide.
What is Zendesk?
Before we dig into Zendesk eDiscovery, let’s break down what Zendesk actually is. At its core, Zendesk is a customer service software that helps companies maintain their customer relationships with innovative tools known as the Zendesk Suite. This centralized, omnichannel workspace helps agents focus on customer interactions regardless of where they live.
Let’s dig into the main features of the Zendesk Suite.
1. Ticketing system
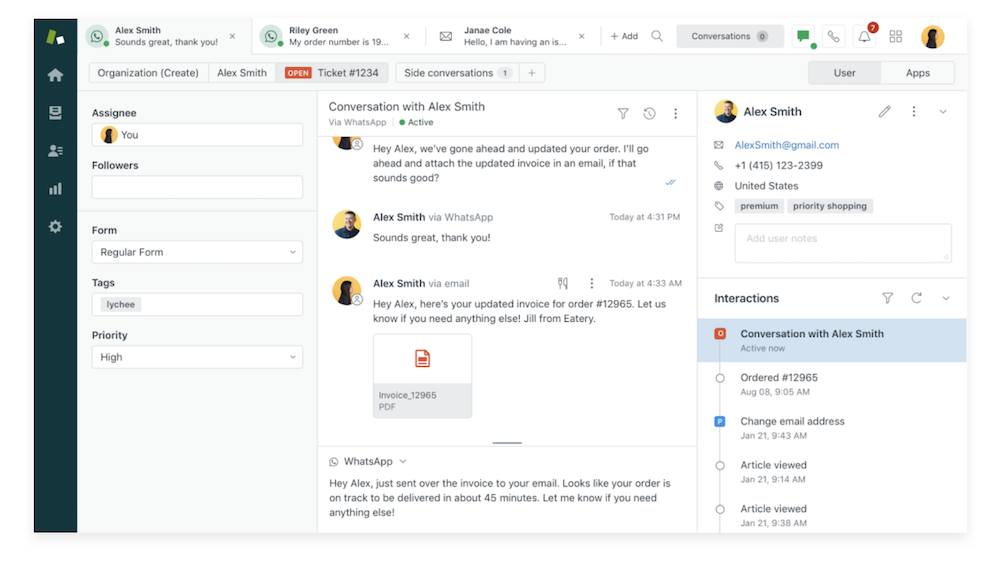
Zendesk’s ticketing system is the core of how Zendesk works. Between chat, email, social media, and more, Zendesk pulls all customer inquiries into one centralized hub called the Agent Workspace. Regardless of where conversations happen, Zendesk collects every customer submission, turns it into a ticket, and queues it up in one place for support agents to take care of. This makes it easy for your agents to track, prioritize, and solve customer inquiries and gives them a holistic view of the customer profile and journey. Each customer has a continuously updated “essentials card,” which shares their contact information, time zone, language, interaction history, and list of websites viewed.
2. Messaging and live chat
Zendesk’s messaging and live chat feature ensures businesses can stay connected with their customers on any channel. Whether you want to message a customer in the live chat on your website, on social apps like WhatsApp and Facebook, or through productivity tools like Slack, Zendesk allows you to frictionlessly continue the conversation from place to place. Additionally, you can create pre-automated, customized messages to get ahead of customers’ questions or even connect third parties in group chats to expedite answers and reduce back-and-forth interactions.
3. Help center
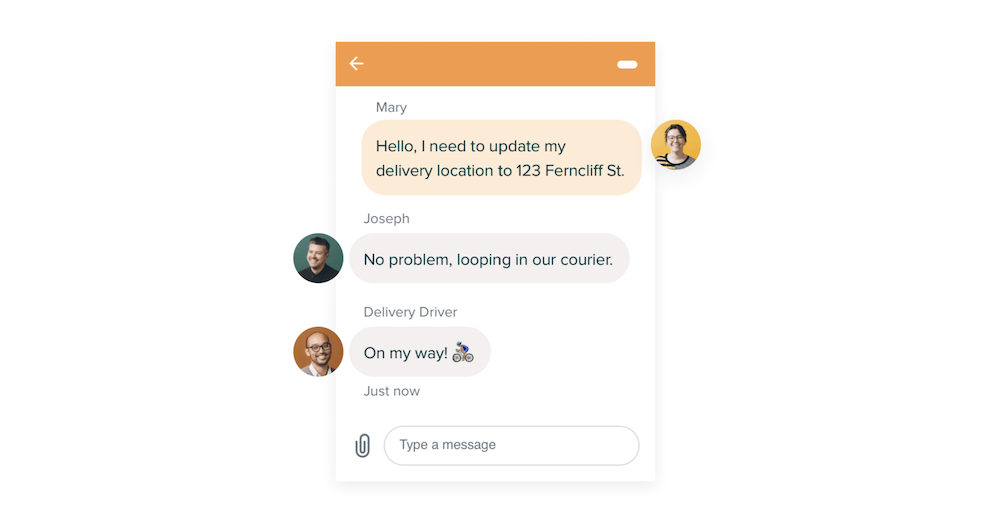
Zendesk’s Help Center is where you can build a knowledge base to help customers find the information they need. The Help Center can also be used as an internal knowledge base for agents or IT teams. Whether it’s a how-to article or FAQ page, strong Help Center content empowers your customers and employees to solve issues on their own. You can elevate your Zendesk Help Center by customizing the theme, integrating it into your product or website, and allowing your team to update and publish new content over time.
Zendesk has also incorporated AI tools that offer insights into what information customers are searching for and that suggest content to add or update. Its generative AI features can also add and revise content plus create conversational responses to customers.
 Via Zendesk
Via Zendesk
4. Voice
Zendesk’s integrated voice software, called Zendesk Talk, enables you to take customer calls from the main interface so you don’t need to toggle back and forth between communication channels. Not only does this help keep things organized, but it also shows agents key customer information and previous interactions so they have context going into each call. Once the call or voicemail has concluded, it’s logged as a ticket, and the recording is attached for easy reference.
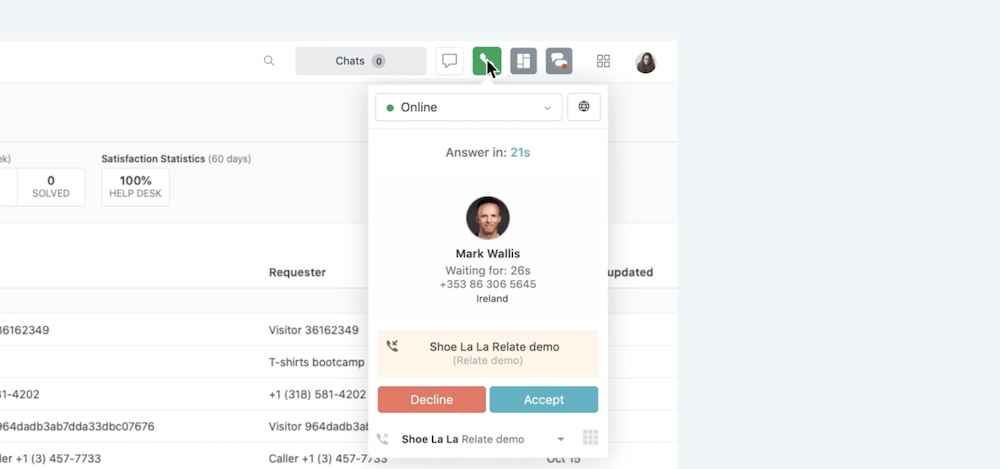
5. AI chatbots
Zendesk’s generative AI-powered chatbots (previously called Answer Bot) help customers answer questions without agent intervention. Bots free up support teams’ time by automating common Q&As and can also detect relevant content in the Help Center to send along as well.
Zendesk’s bots can operate across multiple communication channels like email, messaging, or even third-party integrations like Slack. If a customer’s question can’t be answered, a bot can direct them to a support agent for more personalized assistance.
The platform trains bots on common customer inquiries and past conversations to help target help. You can also build custom bots for your organization.
 Via Zendesk
Via Zendesk
6. Community forum
Zendesk Gather allows you to set up a community forum where customers can engage with one another, post topics for discussion, share feedback, and ask questions. Organizations can seed the community with posts to promote conversations and moderate discussions. They can also monitor and manage members’ access, granting and denying access permissions to different groups.
Agents can escalate posts and turn them into tickets to continue conversations and view customers’ community activity in the Agent Workspace.

7. Reporting
Zendesk builds in robust reporting and analytics features that offer instant visibility into customer behavior. Organizations can gather data on customer support in every channel so they can address problems, identify key trends, improve agent productivity, and use insights to improve the customer experience. Pre-built and customizable dashboards give admins a way to slice and dice data easily and quickly.
8. Zendesk Sunshine
Zendesk Sunshine is a flexible messaging platform with an API that allows users to develop custom apps that connect to external customer data. Sunshine currently connects with more than 1,200 apps, including Slack, Jira, Salesforce, Teams, and Zoom, among many others.
Sunshine Conversations allows organizations to add additional messaging channels, third-party bots, and AI channels to elevate the customer experience, allowing customers to browse products, schedule reservations, and make payments in a conversation.
 Via Zendesk
Via Zendesk
How do I collect data from Zendesk?
Now that you have an overview of the main features in the Zendesk Suite, let’s talk about how to collect relevant data.
When it comes to Zendesk eDiscovery, your most valuable data will likely live in tickets. Whether it’s an email with an attached document or a message with an image, different interactions from different channels are consolidated into a record of tickets. Each one holds a piece of the customer journey and may be vital to find, collect, and preserve for legal or compliance reasons.
The native option:
You can export Zendesk tickets to a JSON, CSV, or XML file if your account owner has this feature enabled. When collecting for Zendesk eDiscovery at scale, however, we don’t recommend relying on the native export feature, as there are a few major limitations:
- Only customers that have the Support Professional or Support Enterprise plan have access to the export feature.
- None of these exports include ticket attachments. The XML file will provide a link to the attachments but will not download the attachment itself, leaving a large gap in the conversation.
- None of these exports include suspended tickets.
- Only the JSON export option, not the XML option, is available for accounts with more than 200,000 tickets.
- Accounts with more than 1 million tickets are downloaded in JSON format, but only in 31-day increments.
- Customers cannot filter data before exporting it. So, even if you only need to sort through a certain ticket type or date range, you will have to manually sort through a massive data set.
When all is said and done, the JSON export is often the only export available, and its unfriendly formatting makes it extremely difficult to understand tickets in context. Not to mention that when accounts break the 1 million ticket barrier, customers lose access to data that’s over 31 days old.
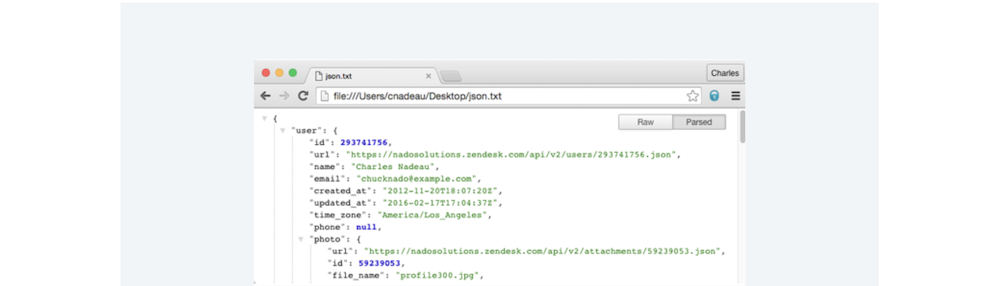
Bottom line: The native export option gives users an incomplete picture of their data, making collections insufficient for Zendesk eDiscovery. However, Zendesk does offer API access to help alleviate these issues, which we’ll cover next.
Does Zendesk have an API?
Yes, Zendesk does have a Support API to help customers collect ticket data; however, you’ll need to work with a trusted eDiscovery partner to turn incomprehensible JSON files into review-ready data. By leveraging this API connection with the right eDiscovery partner, users can collect:
- Tickets (open, closed, suspended, and deleted)
- Attachments included in tickets
- Labels for attachments and pages
- Ancestors for the page/attachments
- Ticket ID (#)
- Ticket name
- Ticket type
- Organization
- Ticket status
- Assignee
- Requester
- Group
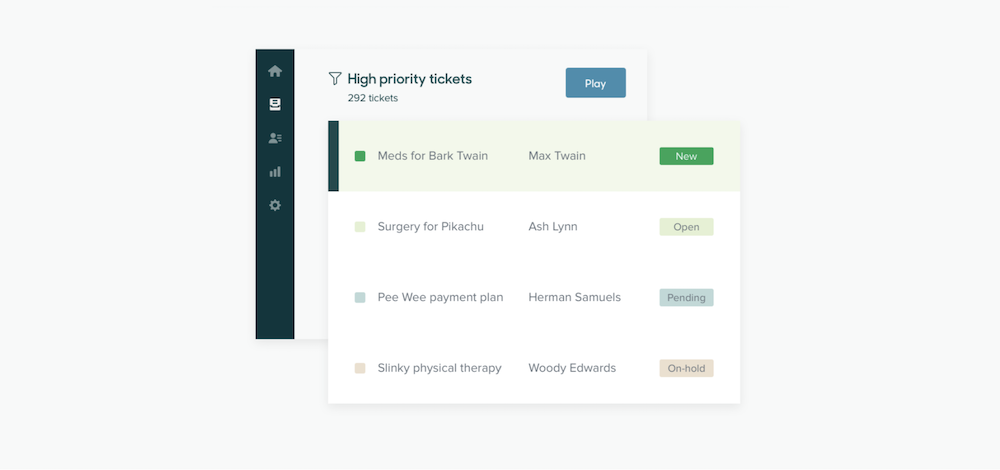
- Ticket priority
- List of tags
We highly recommend connecting to Zendesk’s API via a Zendesk eDiscovery partner. It’s the only way to ensure that you have full contextual knowledge of your tickets and can quickly identify what’s relevant to your investigation. Although the API connection might be the first step in successfully navigating Zendesk eDiscovery, there’s more you need to know.
Let’s get into some key considerations and best practices.
Zendesk eDiscovery strategy
Whether you’re just starting out with Zendesk eDiscovery or have already taken some kind of initiative, each of these steps is crucial to building a successful eDiscovery strategy for Zendesk. We understand that no organization or legal team is the same, so we made this an adaptive guide.
Step 1: Understand your needs
As obvious as it may seem, the first step in launching a successful Zendesk eDiscovery strategy is understanding your needs. Whether you need to collect data for a one-off discovery request or are tasked with archiving millions of tickets, it’s important to investigate your organization’s relationship to Zendesk data. To do this, ask yourself questions like:
- How big is my company?
- How regulated is our industry?
- How frequently do we encounter litigation?
- How are my people engaging with Zendesk?
- What personally identifiable information (PII) might exist in Zendesk?
- How are we retaining data? Deleting data?
- What data might we need to archive?
By asking these questions, you can start to get a more holistic sense of your information governance needs. For example, if your company has thousands of customers who regularly engage with Zendesk, and you operate in a highly regulated industry where sensitive information is being shared, you’re likely dealing with a large data set. Plus, you also face significant risk if the right information isn’t discoverable — or worse, if it’s been erased. If this is the case, you know that solely relying on Zendesk to accurately preserve and search for your data isn’t sustainable.
Whether you’re a large or small organization, if your Zendesk account holds critical information, it should be accessible, secure, and private. If you’re not confident this is the case, it’s time to reassess your Zendesk eDiscovery efforts.
Step 2: Anticipate future risks
You should be thinking about where your Zendesk environment is today but also where it’s going. When assessing your Zendesk eDiscovery needs, you’ll likely come across both short-term and long-term problems. While it’s important to solve for immediate needs, getting ahead of future risk should always be top of mind. A few potential legal and compliance gaps specific to Zendesk include these:

These are just a few roadblocks that organizations might hit down the line when conducting Zendesk eDiscovery. Depending on your size, industry, and use of the platform, these scenarios could look different. No matter your circumstances, one thing’s for certain: it’s best to know what you’re up against.
Step 3: Establish a company policy for Zendesk
After you’ve fleshed out potential Zendesk eDiscovery challenges, one of the best ways to get ahead of them is to establish a company policy for Zendesk. This is essentially your central documentation or “north star” for Zendesk data governance. From outlining retention periods for different data types to technical instructions on how to collect and filter data, this policy should lay the groundwork for legal and compliance preparedness.
If you’re ready to start drafting your Zendesk policy, we recommend covering the following areas as a start:
- What types of tickets are there? What are they labeled?
- What types of tickets pose a higher risk than others?
- What sensitive data lives in what tickets?
- What sensitive attachments might live in tickets?
- What regulatory obligations require the retention of certain tickets?
- What regulatory obligations require the deletion of certain tickets?
- If this, then that scenarios (e.g., What is the workaround if an attachment needs to be saved but a ticket needs to be deleted?)
- How to collect, preserve, search, and export data, step by step
Remember that every organization looks different, so this list can be expanded or condensed to align with your priorities.
Step 4: Implement an eDiscovery solution
Even with all of your policy ducks in a row, Zendesk still has some technical limitations that will stop you in your tracks. To ensure your Zendesk eDiscovery plan is the strongest it can be, you’ll want to implement a trusted eDiscovery solution to help you forensically collect, process, and search across all of your tickets.
Since litigation rarely comes up for many companies, far too many legal teams feel that an in-house solution is overkill. However, the opposite couldn’t be truer. Companies that don’t take a proactive approach waste countless hours, dollars, and resources waiting for litigation to strike. Not to mention, having the right information at your fingertips is useful for any internal investigations and audits that might arise. From service-level agreement discussions to customer service complaints to inappropriate language and harassment, Zendesk data can prove relevant in many scenarios.
If you’re ready to look for a Zendesk eDiscovery solution, at a minimum, it should have the following features:
- An API connection with Zendesk to extract the most defensible data possible, including attachments
- The ability to choose which Zendesk data you collect and preserve
- Continuous sync and archive of specific data if needed
- Powerful processing features including but not limited to metadata extraction, OCRing, natural language processing, and custom classifiers
- Forensic-level search
Beyond these Zendesk-specific features, your eDiscovery solution should check some other crucial boxes as well. Flexible deployment, top-tier security measures, and compatibility with review platforms are just a few of the top things to look for in eDiscovery software. By bringing a Zendesk eDiscovery solution in-house, you’ll increase efficiency and cut back on spending in the long run.
Step 5: Make a long-term eDiscovery and preservation plan
As more and more apps like Zendesk emerge, the more complex information governance gets. For this reason, it’s important to have a sustainable eDiscovery solution that can adapt to any new technology that comes your way.
It’s best to look for a “master tool” for your entire tech stack to provide long-term value for your company.
Maybe right now your priority is to find something cheap and easy for Zendesk, but down the line, you may wish you’d considered a tool that integrates with Slack, Google Workspace, Jira, and the dozens of other applications you may use. From this lens, it’s best to look for a “master tool” for your entire tech stack to provide long-term value for your company.
You want a solution that will continually process, store, and archive the data you need, so you don’t need to worry about one-off, half-baked data exports. Additionally, a solution that applies retention periods to relevant data will ensure nothing slips through the cracks.
We hope our guide gave you a better understanding of the Zendesk platform, its discovery capabilities and limitations, and the steps to create a proactive Zendesk eDiscovery plan. Remember that executing your plan is an ongoing process and requires constant innovation and staying up to date on your organization’s use of the platform.
About Onna for Zendesk
With Onna, organizations that use Zendesk can centralize their eDiscovery efforts by integrating Zendesk and all of their other cloud applications in the same place. This delivers exceptional eDiscovery capabilities for Zendesk users — and Zendesk users who happen to also use Google Workspace, Slack, Microsoft, and more.
Onna’s open API integrates directly with Zendesk to simultaneously collect and process all available data in real-time. Our rapid machine learning, indexing, and OCR, paired with our precise search capabilities, make it easier than ever to customize your collections and avoid unnecessary processing costs. You can find what you need for immediate one-off collections or sync and archive your Zendesk data to have the most up-to-date, search-ready repository of information.
For example, in a one-time collection project for a leading online food ordering and delivery platform, we synced data, extracted their metadata and text, and identified over 6,000 tickets containing sensitive information, enabling the client to search for and delete the necessary data from Zendesk.
To learn more about how Onna collects data from Zendesk, see here.