 eDiscovery
eDiscovery Collections
Collections Processing
Processing Early Case Assessment
Early Case Assessment Information Governance
Information Governance Data Migration
Data Migration Data Archiving
Data Archiving Platform Services
Platform Services Connectors
Connectors Platform API
Platform API Pricing Plans
Pricing Plans Professional Services
Professional Services Technical Support
Technical Support Partnerships
Partnerships About us
About us Careers
Careers Newsroom
Newsroom Reveal
Reveal Logikcull by Reveal
Logikcull by Reveal Events
Events Webinars
Webinars OnnAcademy
OnnAcademy Blog
Blog Content Library
Content Library Trust Center
Trust Center Developer Hub
Developer Hub
Introduction
Confluence and Jira are indispensable tools for the modern workplace: they help teams stay organized and efficient. They connect scattered information into a single source of truth and facilitate the software development work of agile teams.
But the unstructured data these tools create can pose serious headaches for the unsuspecting eDiscovery team. Traditional eDiscovery tools are accustomed to dealing with structured data from databases and emails, not wikis, discussions, screenshots, and other project documentation that are commonly stored in Confluence and Jira. As organizations generate more and more of this unstructured data — 90% of all enterprise data is unstructured, according to a report from IDC — organizations need a strategy and technology to collect, process, and produce it for early case assessment, investigations, and litigation.
In this guide, we’ll teach you everything you need to know about extracting Confluence and Jira data for eDiscovery and compliance. We’ll cover these topics:
- An overview of what Confluence and Jira do and their features
- The challenges of collecting Confluence and Jira data
- Confluence and Jira roles, permissions, and subscription plans
- Data retention in Confluence and Jira
- The best Confluence and Jira plans for eDiscovery
- How to establish a successful Confluence and Jira eDiscovery strategy
- How Onna simplifies eDiscovery in these platforms
Let’s get into it.
What are Confluence and Jira?
Confluence and Jira are collaborative project management and documentation tools created by software company Atlassian.
Confluence
Confluence is a collaboration and documentation platform designed to enhance teamwork and streamline information sharing within organizations. More than 75,000 companies use Confluence to create rich content, including text, images, tables, files, and macros, making it a versatile tool. Common uses include knowledge base articles, meeting notes, project documentation, and other collaborative content.
Pages
The platform is structured around pages, which users can organize into spaces to arrange content based on projects, teams, or topics. Common uses include meeting notes, troubleshooting guides, and policies. Confluence supports real-time collaborative editing, allowing multiple users to work simultaneously on a page while tracking changes and maintaining a version history.
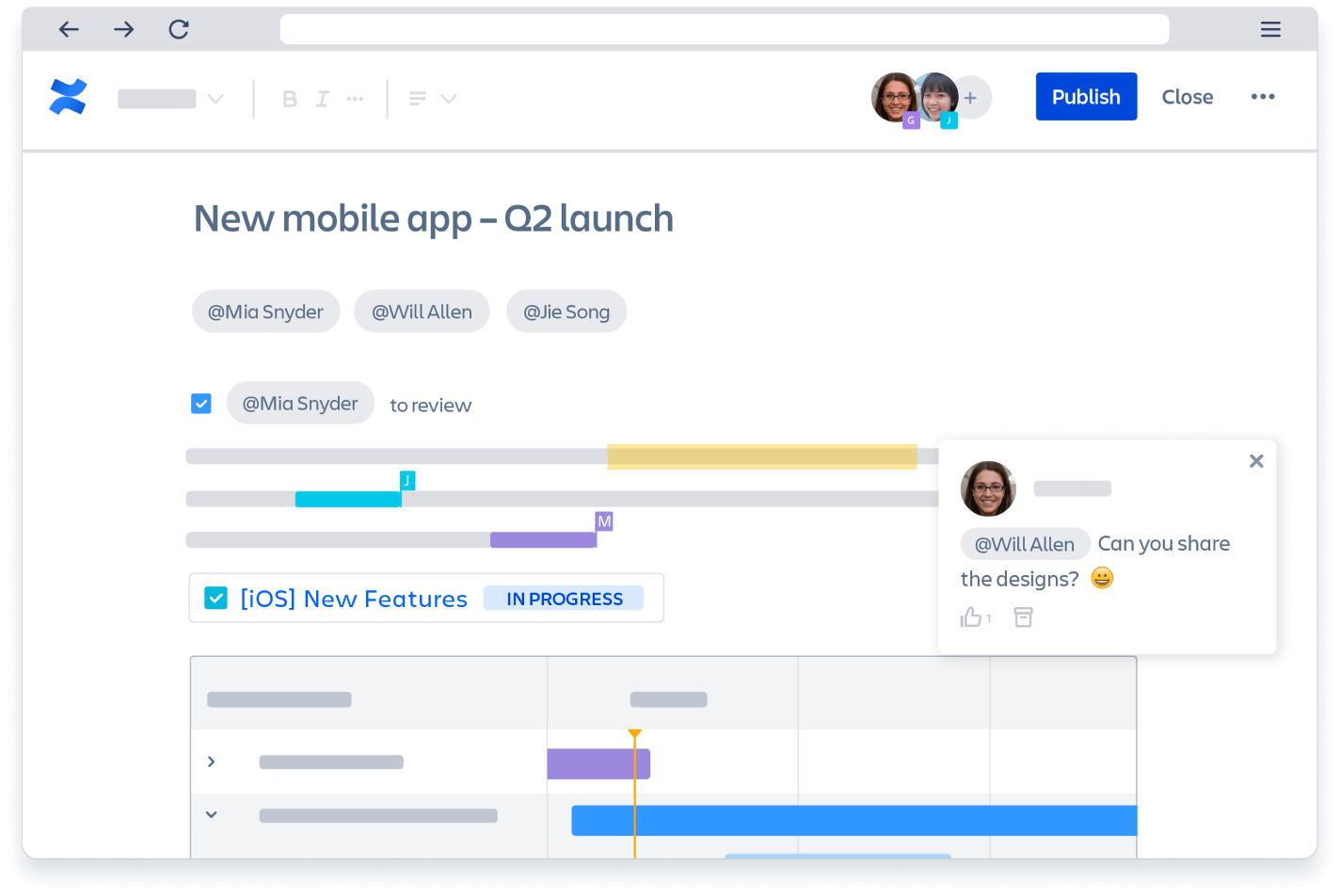
Screenshot from Atlassian's Confluence
Spaces
Spaces are where pages are stored. They are collaborative workspaces where users can keep all their content organized. Each space includes a homepage and a blog, making it easy to share information with an entire team.
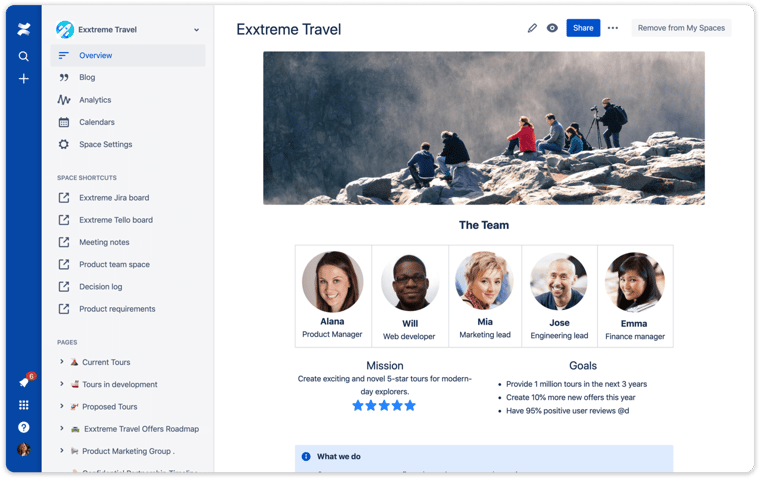
Screenshot from Atlassian's Confluence
Page trees
Hierarchical page trees help organize content in spaces. Pages can be nested and otherwise configured to meet users’ needs.
Integrations
Integration with other Atlassian tools, such as Jira and Trello, plus 3,000 other applications, fosters seamless connections between project management, development, and documentation efforts.
Jira
Jira is a versatile, widely adopted project management and issue-tracking software. More than 65,000 companies have adopted Jira given its flexibility and extensibility: it can be configured to work with thousands of apps and integrations.
Initially designed to support software development projects, Jira has expanded its capabilities to accommodate a broad spectrum of projects and workflows across different industries.
Issues
The central concept in Jira is the “issue,” which can represent work items such as tasks, bugs, stories, or epics, large bodies of work that can be broken down into smaller tasks or stories, within a project. Issues are highly customizable, allowing users to include essential details like summaries, descriptions, assignees, priorities, and statuses.
Projects
Projects in Jira serve as containers for organizing work, each with its own set of issues, workflows, and configurations tailored to the specific needs of a team or organization. Features like comments, attachments, and notifications enable team members to share information seamlessly. Reporting and dashboard functionalities provide teams with insights into project progress and performance through visualizations and charts.
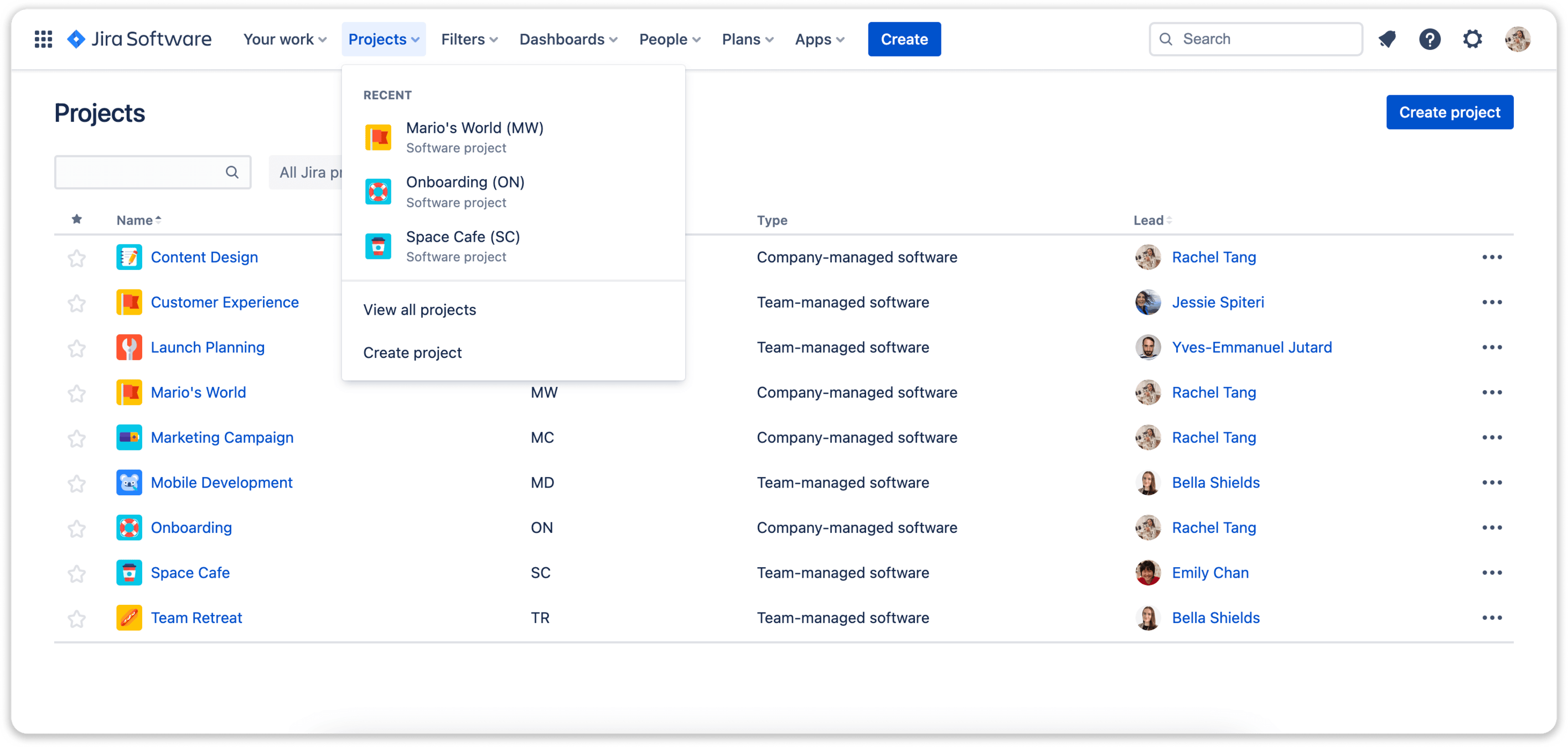
Screenshot from Atlassian's Jira software
Boards
A Jira project serves as the repository for all the issues that must be resolved to accomplish a specific objective, whereas a Jira board acts as the management interface for these issues, guiding them from creation to completion. Boards in Jira offer a visual representation of work, making it easier for teams to prioritize, track, and manage tasks within a project.
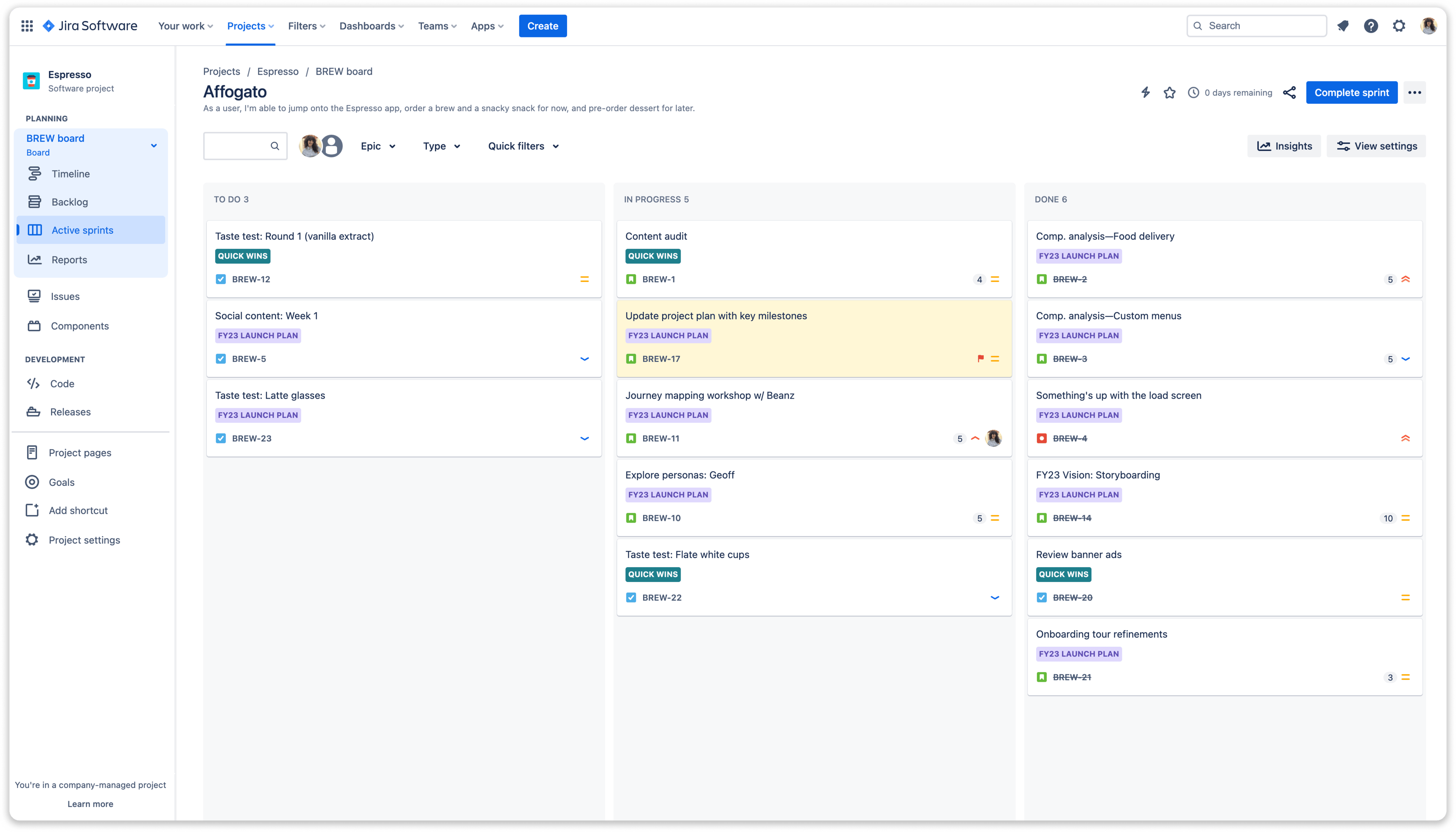
Screenshot from Atlassian's Jira software
What makes Confluence and Jira data unique?
Data in Confluence and Jira is characterized by structured project information, issue histories, user interactions, and rich documentation. Understanding the unique nature of this data is crucial for effective eDiscovery.
While Confluence and Jira have some commonalities in terms of how they approach user management, integration, and collaboration, the data they generate differs markedly.
Confluence
While Jira is more structured, Confluence accommodates both structured and unstructured data.
Confluence stores data in pages, which can contain rich content, such as text, images, tables, multimedia, and attachments. Multiple users can collaborate on a Confluence page simultaneously, with changes reflected in real-time. Users can also comment and ask questions on pages. The application also maintains each page’s version history, so users can track changes and revert to previous versions. Users can also create parent-child relationships between pages to organize content.
Additionally, Confluence supports macros and add-ons that enhance its basic functionality. Potential add-ons include dynamic content, charts, and integrations with external tools. Confluence often integrates with Jira, allowing users to embed Jira issues, reports, and project information directly into Confluence pages.
All of this dynamic data makes these platforms incredibly powerful — and incredibly difficult to identify, process, and export it for eDiscovery.
Jira
Jira’s data revolves around its issue-tracking capabilities. Each issue represents a task, story, bug, or any unit of work. Collectively, issues form a structured dataset. Within that dataset, users can define custom fields to capture specific information.
Because Jira is a project management tool, it may reflect fields to capture Agile and Scrum concepts, such as sprints, backlogs, and boards. Users can also attach files and link related items to issues, including images, documents, and links to external resources.
The application creates comprehensive audit trails that record all changes to status, assignees, comments, and modifications. It also keeps a log of user activities, recording who performed specific actions and when, as well as other time-tracking features.
Understanding roles and permissions in Confluence and Jira
Confluence and Jira rely on robust role-based access controls. Understanding the nuances of user roles and permissions ensures secure, controlled access to information in eDiscovery.
Confluence
Confluence roles determine each user’s access levels and permissions.
- Space administrators have control over a specific Confluence space, including permissions, templates, and configurations.
- Space contributors can create and edit content within a space but do not have administrative privileges.
- Space watchers receive notifications about changes in a space but do not have editing rights.
Jira
Jira has a similar set of roles and permissions.
- Administrators are the highest user tier. They have control over all aspects of Jira, including user management, system configuration, and customization.
- Project administrators have control over configurations and settings within a specific project. They can manage project versions and oversee project components.
- Developers have access to most project functionality, including the ability to create and update issues.
- Reporters can create issues and add comments but typically have limited control over other aspects of project configuration.
- Viewers have read-only access to projects and can see project details but cannot create or edit issues.
How to choose the best Confluence and Jira plan for eDiscovery
The optimal Confluence and Jira plan for eDiscovery is the one that allows your organization to meet its data governance, compliance, and efficiency goals.
Both Confluence and Jira offer four plan tiers: Free, Standard, Premium, and Enterprise. Each tier comes with varying features, and the right choice will depend on your organization’s size, needs, and budget. For example, the Standard Jira plan is designed for companies with up to 35,000 users, while the Standard Confluence plan can handle up to 50,000 users.
There are other considerations as well, namely, reducing the burden of preserving and collecting Confluence and Jira data. Here is a quick overview of the eDiscovery-related features in each paid tier of these platforms:

If you choose the Data Center license (rather than the Cloud) for either Confluence or Jira, you can export data this way. However, the data is exported only in CSV format, and you can only perform one export at a time. Keep in mind that the export will include all data, including personally identifiable information and restricted content. Moreover, the export can take a long time. To reduce the impact to the system, Atlassian limits the rate at which users can export data.
Managing Confluence and Jira data retention
Jira does not have a specific data retention policy, but Confluence does to help users manage the burden of historical versions of pages and files. In Confluence, you can set global retention rules for all spaces and define exemptions. For example, you can exempt certain spaces from the application of specific rules.
Retention rules allow you to automatically delete historical versions of pages and attachments and purge deleted items from the trash. You can set retention rules for historical page versions, historical attachment versions, and items in the trash. The three rule criteria you can set are as follows:
- Keep all, which is the default: Retains all historical versions and does not automatically purge items from the trash
- Keep by age: Retains all versions and items in the trash for a specific amount of time
- Keep by number: Retains a maximum number of versions (and does not apply to items in the trash)
Confluence runs a sweep every 10 minutes to delete data that does not satisfy the retention rules. It deletes items in small batches to reduce the risk of performance impacts to your site. You can also schedule a sweep to delete all information in one cycle, but that could affect your site’s performance.
You can also combine two data retention policies. For instance, if you use keep by age plus keep by number, you can set a maximum of 3 years and 10 versions to keep, and the remaining data will be deleted.
Note that Confluence always retains the latest version of pages and attachments.
An adaptive Confluence and Jira eDiscovery strategy
Whether you’re just starting to use Confluence or Jira or have already attempted to extract data from it, you need a robust eDiscovery strategy for data from both platforms. But, because no two organizations or legal and compliance teams are the same, we’ve put together these steps that you can adapt to your own needs.
Step 1: Understand your needs
As obvious as it may seem, the first step in launching a successful Confluence or Jira eDiscovery strategy is understanding your needs. Whether you need to collect data for a one-off discovery request or are tasked with archiving millions of tickets, it’s important to investigate your organization’s relationship to Confluence and Jira data. To do this, ask yourself questions like these:
- How big is my company?
- How regulated is my industry?
- How frequently do we encounter litigation?
- How are employees engaging with Confluence? With Jira?
- How often are employees engaging with Confluence? With Jira?
- How dynamic is our content within Confluence? Within Jira?
- How is the data being stored in Confluence or Jira, and how are guests or external parties collaborating with us in these systems?
By asking these questions, you can start to get a clearer idea of your data governance and eDiscovery needs. For example, if your company has thousands of people who regularly engage with Confluence or Jira and operate in a highly regulated industry where sensitive information is being shared, you’re likely dealing with a large, complex data set — plus greater risk if the right information isn’t discoverable — or worse, isn’t carefully preserved.
No matter the size of your organization, if your Confluence or Jira account stores critical information, it should be accessible, secure, and private. If you’re not confident this is the case, it’s time to reassess your eDiscovery strategy for these platforms.
Step 2: Reassess your Confluence or Jira plan
Once you have a better understanding of your needs, ensure that your current subscription to Confluence or Jira supports them. If it doesn’t, an upgrade can improve your data access. If you don’t already have a paid plan, obtaining one is essential to ensure you can control and protect your data.
Step 3: Establish a company policy for Confluence and Jira
After you’ve aligned your plan with your eDiscovery and data needs, you should establish a written policy for how these platforms should be used and how they will be monitored. Your policy should address access controls for this data and set retention periods for different categories of data. It should also include technical instructions on how to collect, preserve, search, and export data from the platform, setting a baseline for legal and compliance preparedness.
Here are some basic policy elements to consider:
- Outlining who should receive which user roles and configuring permissions accordingly
- Optimizing your admin roles and user permissions for compliance and security
- Identifying which data types are relevant to retain or delete and why
- Putting restrictions in place around user behavior and explaining why
- Identifying the limitations you currently face and how you plan on filling those gaps in the future
Although there is no one-size-fits-all approach, a well-documented policy can help streamline communication between teams, help you spot and avoid risk, and allow you to constantly iterate and improve on your processes for eDiscovery in Confluence and Jira.
Step 4: Implement an eDiscovery solution
To strengthen your eDiscovery strategy, you’ll want to implement a trusted eDiscovery solution to help you forensically collect, process, and search data across your Confluence or Jira environment.
For the majority of companies, litigation is, blissfully, a rare occurrence. So it may seem that they’re overspending on an in-house solution. However, companies that don’t take a proactive approach to planning for eDiscovery waste countless hours, dollars, and resources waiting for litigation to strike.
Even more importantly, having the right information at your fingertips is useful for any internal investigations and audits that might arise. Confluence and Jira data could be relevant in a variety of scenarios:
- Confluence pages might contain evidence of an organization’s efforts to comply with regulations
- Confluence notes could establish a lack of prior notice about a defect in a products liability case
- Confluence documentation might show that employees were trained and were aware of policies and procedures in an employee misconduct case
- Jira’s time-tracking feature could reveal what hours an employee worked for a wage and hour claim
- Jira customer service tickets could show that the company took reasonable steps to warn consumers about warranty issues to defeat a claim of insufficient notification
If you’re ready to look for an eDiscovery solution that can handle Confluence or Jira data, at a minimum it should have the following attributes:
- An API connection with Confluence or Jira to extract the most defensible data possible, including attachments
- Ability to choose which Confluence or Jira data you collect and preserve
- Continuous sync and archive of specific data if needed
- Powerful processing features, including metadata extraction, OCR, natural language processing, and custom classifiers
- Forensic-level search
Beyond these features specific to these platforms, your eDiscovery solution should check some other boxes as well. Flexible deployment, top-tier security measures, and compatibility with review platforms are just a few of the top things to look for in eDiscovery software.
By bringing an eDiscovery solution for Confluence and Jira in-house, you’ll increase efficiency and cut back on spending in the long run.
Step 5: Make a long-term eDiscovery and preservation plan
As more and more apps like Confluence and Jira emerge, the more complex information governance gets. For this reason, it’s important to have a sustainable eDiscovery solution that can adapt to any new technology that comes your way.
Maybe your priority right now is to find something cheap and easy for Confluence and Jira, but down the line, you may wish you’d considered a tool that integrates with Slack, Google Workspace, Box, and the dozens of other applications you may use. From this lens, it’s best to look for a master tool for your entire tech stack to provide long-term value for your company.
We hope our guide gave you a better understanding of the Confluence and Jira platforms, their discovery capabilities and limitations, and the elements of a proactive eDiscovery plan. Remember that executing your plan is an ongoing process that requires constant innovation and vigilance.
About Onna for Confluence and Jira
With Onna, organizations that use Confluence and Jira can centralize their eDiscovery efforts by integrating this data with that from other cloud applications in a single place. This not only opens up new eDiscovery capabilities for Confluence and Jira users but also benefits those whose digital workplace includes applications like Google Workspace, Zoom, Slack, and more.
Onna integrates directly with Confluence and Jira via no-code connectors to simultaneously collect and process all available data in real-time. Advanced processing, machine learning, and indexing make customizing your collections and avoiding unnecessary processing costs easier than ever.
Once your Confluence or Jira data is in Onna, your team has immediate access to it. Gain insights, analyze risk, reduce downstream costs, and export your case data into your preferred review platform, all with the easy-to-use Onna eDiscovery solution.
Sound like a solution that meets your needs? Get a demo and learn how Onna integrates with Confluence and Jira today.